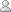

The TokenSearch class in the org.jqurantree.search package allows searches to be performed against the orthography model. It is possible to search for tokens using an exact string match, or a substring search can be performed which will look for text within a token. The TokenSearch class is used by performing the following steps:
| Step 1. | Initiate a new TokenSearch instance by specifying which encoding type to use, e.g. Buckwalter transliteration, or Unicode. All string comparisons will be performed using the specified encoding type. |
| Step 2. | Define the search criteria through calls to findToken() and findSubstring(). |
| Step 3. | Run the search by calling the getResults() method. |
The findToken() and findSubstring() methods add to the list of search criteria, and each take as parameter a string in the specified encoding. The difference between the two methods is that findToken() will list all tokens matching the string parameter exactly, whereas findSubstring() will list all tokens containing the text parameter as a substring. After performing the search, the getResults() method returns an analysis table with 4 columns:
- The chapter number.
- The verse number.
- The token number.
- The token's text in the specified encoding.
The returned analysis table will list all matching tokens together with their location. The search criteria are combined using a Boolean OR, so that if any of the search criteria match, the token will be listed.
Searching without Diacritics
The SearchOptions enumeration can be used to perform a search that is not sensitive to diacritics. When constructing a new TokenSearch instance, SearchOptions.RemoveDiacritics can be specified:
TokenSearch search = new TokenSearch(
EncodingType.Buckwalter, SearchOptions.RemoveDiacritics);
Example
The token search example contains a Java program which uses the search API to perform both exact string matches and substring matches.