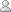

Unicode deserialization is supported by JQuranTree to allow the Uthmani Script to be loaded into the orthography model. The decoding process is reversible, and is tested via the round trip method: A Unicode encoder is used to serialize the orthography model back into Unicode, and tests are run to ensure that the original character data is recovered.
Decoding Unicode Character Data
Since the Unicode encoder and decoder need only support the Uthmani Script, it is sufficient that they handle only the characters found within that XML document. The orthography model represents the Quranic text as a sequence of ArabicCharacters. Each character has a CharacterType and zero or more DiacriticTypes. Orthographic characters include letters, and other Quranic symbols. The diacritics are tashkīl (vowels).
Unicode decoding is performed using table lookup. For each Unicode character in the Uthmani script, the orthographic character type and diacritic type are looked up (see Fig 1. below). A sequence of several Unicode characters may be decoded as a single orthographic ArabicCharacter. If table lookup results in a character type, then a new orthographic character is formed. Otherwise, if the lookup results in only a diacritic type, then the diacritic will be combined with the previous orthographic character.
| UNICODE | ORTHOGRAPHY MODEL | |||
| Decimal | Hex | Glyph | Character | Diacritic |
| 1569 | U+0621 | 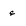 |
Hamza | - |
| 1571 | U+0623 | 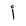 |
Alif | HamzaAbove |
| 1572 | U+0624 |  |
Waw | HamzaAbove |
| 1573 | U+0625 | 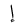 |
Alif | HamzaBelow |
| 1574 | U+0626 | 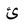 |
Ya | HamzaAbove |
| 1575 | U+0627 | 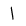 |
Alif | - |
| 1576 | U+0628 | 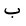 |
Ba | - |
| 1577 | U+0629 | 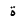 |
TaMarbuta | - |
| 1578 | U+062A |  |
Ta | - |
| 1579 | U+062B |  |
Tha | - |
| 1580 | U+062C | 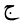 |
Jeem | - |
| 1581 | U+062D | 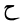 |
HHa | - |
| 1582 | U+062E | 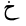 |
Kha | - |
| 1583 | U+062F | 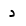 |
Dal | - |
| 1584 | U+0630 | 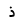 |
Thal | - |
| 1585 | U+0631 | 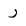 |
Ra | - |
| 1586 | U+0632 | 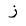 |
Zain | - |
| 1587 | U+0633 | 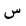 |
Seen | - |
| 1588 | U+0634 | 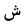 |
Sheen | - |
| 1589 | U+0635 | 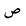 |
Sad | - |
| 1590 | U+0636 | 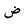 |
DDad | - |
| 1591 | U+0637 | 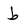 |
TTa | - |
| 1592 | U+0638 | 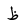 |
DTha | - |
| 1593 | U+0639 | 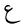 |
Ain | - |
| 1594 | U+063A | 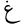 |
Ghain | - |
| 1600 | U+0640 | 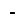 |
Tatweel | - |
| 1601 | U+0641 |  |
Fa | - |
| 1602 | U+0642 | 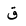 |
Qaf | - |
| 1603 | U+0643 | 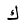 |
Kaf | - |
| 1604 | U+0644 | 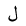 |
Lam | - |
| 1605 | U+0645 | 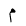 |
Meem | - |
| 1606 | U+0646 | 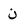 |
Noon | - |
| 1607 | U+0647 |  |
Ha | - |
| 1608 | U+0648 | 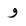 |
Waw | - |
| 1609 | U+0649 | 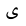 |
AlifMaksura | - |
| 1610 | U+064A | 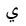 |
Ya | - |
| 1611 | U+064B | 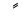 |
- | Fathatan |
| 1612 | U+064C | 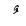 |
- | Dammatan |
| 1613 | U+064D | 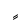 |
- | Kasratan |
| 1614 | U+064E | 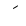 |
- | Fatha |
| 1615 | U+064F | 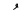 |
- | Damma |
| 1616 | U+0650 |  |
- | Kasra |
| 1617 | U+0651 | 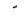 |
- | Shadda |
| 1618 | U+0652 | 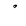 |
- | Sukun |
| 1619 | U+0653 | 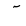 |
- | Maddah |
| 1620 | U+0654 | 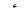 |
- | HamzaAbove |
| 1648 | U+0670 | 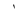 |
Alif | AlifKhanjareeya |
| 1649 | U+0671 | 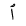 |
Alif | HamzatWasl |
| 1756 | U+06DC | 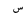 |
SmallHighSeen | - |
| 1759 | U+06DF | 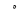 |
SmallHighRoundedZero | - |
| 1760 | U+06E0 |  |
SmallHighUprightRectangularZero | - |
| 1762 | U+06E2 | 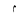 |
SmallHighMeemIsolatedForm | - |
| 1763 | U+06E3 | 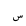 |
SmallLowSeen | - |
| 1765 | U+06E5 | 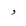 |
SmallWaw | - |
| 1766 | U+06E6 | 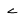 |
SmallYa | - |
| 1768 | U+06E8 | 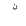 |
SmallHighNoon | - |
| 1770 | U+06EA |  |
EmptyCentreLowStop | - |
| 1771 | U+06EB | 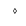 |
EmptyCentreHighStop | - |
| 1772 | U+06EC |  |
RoundedHighStopWithFilledCentre | - |
| 1773 | U+06ED | 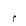 |
SmallLowMeem | - |
Fig 1. Unicode decoding table.
Algorithm for Encoding into Unicode
Any given subset of the orthographic model could have multiple representations in Unicode. This is due to the fact that Unicode allows combining marks to be ordered arbitrarily, and because certain combinations of letters and diacritics (e.g. alif and hamza) can be represented as a single Unicode character.
The encoding algorithm used by JQuranTree was chosen to ensure that round trip testing is possible, i.e. the Unicode serialization used is exactly reversible. Given Tanzil XML, the original sequence of Unicode characters will be recovered after deserializing then reserializing the orthographic model. The Unicode encoding algorithm is shown in Fig 2. below:
| For each ArabicCharacter: | |
| Step 1. | If the letter or Quranic symbol has a diacritic
that forms a well known combination, then map this onto a single
Unicode character. If Hamza above was the diacritic used, then
remove this from the list of diacritics to consider. The 6 well known
combinations are:
- Alif/Waw/Ya + Hamza above
- Alif + Hamza below - Alif + Hamzat wasl - Alif + Khanjareeya (superscript Alif) |
| Step 2. | If Step 1 did not apply, then use the decoding table (Fig 1. above) to determine the Unicode character to use for the letter or Quranic symbol, without its diacritics. |
| Step 3. | Use the decoding table to form Unicode Characters
out any remaining diacritics, in the following order:
- Hamza above
- Shadda - Fathatan - Dammatan - Kasratan - Fatha - Damma - Kasra - Sukun - Maddah |
Fig 2. Unicode encoding algorithm.