
JQuranTree is organized into three parts: The Quranic text itself, a set of access APIs, and a set of analysis APIs. The distinction between accessing and analyzing the Quran is that access is concerned with representing the Arabic text (e.g. chapters, verses, letters and diacritics), whereas the analysis API is built on top of this, providing more sophisticated tools for computational linguistics.
A verified electronic copy of the Arabic Quran
The Uthmani distribution of the Tanzil project is used (http://tanzil.info) and is left unmodified. This is an accurate representation of the Madina Mushaf. The text is stored as a Unicode XML document, with an XML element for each chapter and verse in the Quran.
A set of Java APIs for accessing the Quran
A Java object model is used to represent the orthography of the Quran at different levels of detail. At the highest level, the entire Quran is represented as a single document consisting of chapters with verses. Each verse is a sequence of orthographic tokens. These are pieces of text delimited by spaces, typically a word with its affixes. Unlike in English, determining individual word segments in the Arabic form of the Quran is non-trivial, since multiple segments may be fused into a single token. Segmentation of individual tokens is left to the analysis API.
Continuing downwards, each token is modelled as a sequence of characters. Each character - a letter or other Quranic symbol - may support zero or more diacritics. These are vowels and other marks placed above or below individual letters.
A set of Java APIs for analyzing the Quran
It is intended that with each successive release, JQuranTree will incorporate more sophisticated analysis tools. The initial release will focus on a search feature, allowing substrings to be searched for, with or without diacritics. It is hoped that future releases will include linguistic tools with increasing levels of sophistication. The following analysis features are planned:
- Token segmentation
- Part of speech tagging
- Morphological analysis
- Root extraction
- Word sense disambiguation
The long term aim of the JQuranTree project is provide a complete syntactic and semantic analysis of the Quran, not unlike a parsed corpus. This data is intended to be a free and publicly available resource.
Accessing the Quran
Modelling Quranic Orthography
JQuranTree uses a hierarchal object model to represent the Arabic text of the Quran. Classes Modelling the text of the Quran may be found in the org.jqurantree.orthography package. As illustrated below, the object model is composed hierarchically, with the class at each level acting as container to the class at the level below:
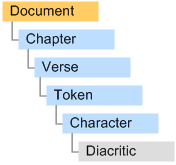
Fig 1. Orthographic object model.
This orthographically motivated representation is designed to support simple and efficient analysis of the text. The representation is neutral with respect to any particular encoding scheme, such as Uncode encoding, or Buckwalter transliteration. An extensible encoding framework is provided to support serialization of the document into different formats.
Arabic Text and Unicode
Unicode is not used as the in-memory representation of the Arabic text since multiple sequences of Unicode characters may map to the same orthographic representation. If JQuranTree used Unicode internally then searching for substrings - with or without diacritics - would require a more involved algorithm.
As with modern standard Arabic texts (e.g. newspaper text), the Quran uses the standard Arabic alphabet. Modern text is rarely vowelized, whereas the Quran contains a comprehensive set of diacritics. Arabic diacritics were themselves originally introduced to encode the Arabic script of the Quran. Orthographic marks are commonly found in the Quran which are only very rarely found in other texts, e.g. the superscript alif. These and other marks in the Quran are used to support both accuracy of pronunciation as well as accuracy of meaning.
 |
Fig 2. Hand written Arabic with different levels of orthography: 1. Pure letter forms. 2. Dotted marks. 3. Diacritic vowels (tashkeel). 4. Pronunciation marks. |
Unicode is supported by JQuranTree for serialization. Any part of the orthographic model may be written to (or read from) Unicode. The Arabic text of the Quran is stored on disk as a single UTF-8 Unicode XML file, which is read when the library initializes.
Buckwalter Transliteration
Buckwalter transliteration is a simple and reversible transliteration scheme which maps Arabic letters and diacritics onto common ASCII characters. In order to support Buckwalter transliteration, the original scheme has been extended to support additional orthographic marks found in the Quran. This extended Buckwalter transliteration scheme is a superset of the original.
Numbering Conventions
JQuranTree uses a 1-based numbering convention to identify chapters, verses and tokens. There are 114 chapters within the Holy Quran, numbered 1 through 114 respectively. Each chapter consists of an ordered sequence of verses, starting with verse number 1. Each verse is further divided into a sequence of orthographic tokens. An orthographic token is delimited by spaces, with the first token having token number 1.
The Location class is used to identify a position within the Quran by chapter number (1-114), verse number (≥ 1), or token number (≥ 1).
Accessing Quranic Text
The Document class, in the org.jqurantree.orthography package, is the top-level class in the orthographic model, and represents all Arabic text of the Quran. When first accessed, this class reads the Unicode XML file, and builds the object model which is then cached. The class provides static methods to access the Quranic text, either by chapter, verse and token numbers, or by Location references.
Examples
The examples below show how to use the org.jqurantree.orthography package to access the Quranic text:
- Using the Location
class
- Converting to simple
encoding
- Converting to Buckwalter
transliteration
- Searching for Bismillah
in the Quran
Analyzing the Quran
Performing text searches
The initial release of JQuranTree contains a search API which may be used search for substrings within the Arabic text of the Quran. The search classes are found in the org.jqurantree.search package.
Examples
These examples show how to use the org.jqurantree.search package to search the Arabic text of the Quran.
- Searching for
occurrences of the The Sun and The Moon
- Searching for "reward"
without diacritics