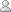

Given a block of Unicode text containing diacritics, locating a letter by offset would require scanning every character, since sequences of diacritics are of variable length. The orthography object model allows access to individual letters within the Arabic text of the Quran. Representing each letter with its own Java object would consume an unreasonable amount of memory for the entire Quran.
Both of these concerns are addressed by using a byte buffer, with a fixed width for each letter, including its diacritics. ArabicCharacter objects are a view on the buffer. They are created on demand and are garbage collected. Each ArabicCharacter is represented by 3 bytes. The first byte encodes the character type. The second and third bytes form a vector of bits. Each diacritic type has a fixed position in the bit vector, and if the bit is set then the diacritic is present.
The maximum range of values possible in this encoding scheme would be 256 character types, and combinations of 16 diacritic types. In practice, only 44 character types and 13 diacritic types are used.
Byte Format Example
Consider the 3rd whitespace delimited token of verse (70:8). The 6 characters of this token would be represented as shown in Fig 2. below:

Fig 1. Orthography of the 3rd token of verse (70:8).
| Arabic | Byte 1 | Byte 2 | Byte 3 |
| Character + Diacritics | Character | Diacritics | Diacritics |
| Alif + HamzatWasl | 0 | 0 | 23 |
| Lam | 22 | 0 | 0 |
| Seen + Fatha + Shadda | 11 | 20 + 26 | 0 |
| Meem + Fatha | 23 | 20 | 0 |
| Alif + Maddah | 0 | 0 | 20 |
| Hamza + Dammah | 28 | 21 | 0 |
Fig 2. Byte representation for the 3rd token of verse (70:8).
The 6 characters of this token are represented by the following 24 bytes:
0, 0, 8, 22, 0, 0, 11, 65, 0, 23, 1, 0, 0, 0, 1, 28, 2, 0
Memory Consumption
The Quranic text contains 6236 verses. Representing all verse character data from Tanzil XML in Unicode would require 1389662 bytes (1.33 megabytes). The bit-packed ArabicText used by the orthography model uses 1242006 bytes (1.18 megabytes). Dividing this by 3, we get 414002 characters for all verse text, including whitespace.