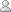

The org.jqurantree.orthography package contains Java classes that model the Arabic orthography of the Quran. This model is organized as a hierarchy of objects:
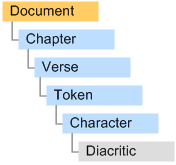
Fig 1. Orthographic object model.
The orthographic model of the Quran is immutable. That is, the model can be read and searched, but cannot be changed. From top to bottom, the orthography model is composed of the following elements: Document, Chapter, Verse and Token. The following definitions are used:
| Document | A structured representation of the entire text of the Holy Quran. Includes all verse text, chapter names, bismillah phrases and any other document-level information. |
| Chapter | The Holy Quran is organized into 114 chapters. Each chapter (sura in Arabic) has a unique name and number. |
| Verse | Each chapter is divided into a sequence of verses (ayāt in Arabic). Within the Uthmani script, there are a total of 6236 verses. These verses contain the actual words used in the Quran. Nearly all chapters in the Quran precede their verses with the phrase bismillah. |
| Token | An orthographic token is whitespace-delimited Arabic text within a verse. This is typically a word with its affixes. In Arabic, a word and multiple particles may be fused together into a single orthographic token. |
The Document class sits at the top of the object model. This class is a singleton, and provides static methods to access other elements. All other orthography elements are instances and provide instance methods. The Verse and Token classes both derive from the ArabicText class. The use of inheritance is logically appropriate since a verse and token are both Arabic text. It is also practical so that ArabicText methods are easily available when working with verses or tokens, e.g. toUnicode() or getCharacter().
Modelling Arabic Text
At the lowest level, the orthography of Arabic text in the Quran is modelled as a sequence of ArabicCharacters. Each Arabic character has a character type and a zero or more diacritics. As an example, consider the 3rd whitespace delimited token of verse (70:8). This is pronounced l-samāu ("the sky"). Within the Uthmani script of the Medinah Mushaf, this token is represented orthographically by 6 letters, with diacritics attached to 5 of these (see Fig. 2 below).

Fig 2. Orthography of the 3rd token of verse (70:8).
Reading from right to left, the second letter has no diacritics, whereas the third letter has 2 diacritics, fathah and shadda. 12 Unicode characters, each of 2-bytes, are required to represent this token using Unicode encoding (6 characters + 6 diacritics).
JQuranTree does not use Unicode to model Quranic orthography, since two different sequences of Unicode may have the same orthographic interpretation. The ArabicText class is used to model the text of the Quran. This class may be found in the org.jqurantree.arabic package.
Instances of ArabicText are immutable, not unlike Strings in Java. Whereas a String is a logical sequence of 2-byte Unicode characters, an ArabicText instance is a logical sequence of ArabicCharacters. The possible character types and diacritic types for each character - as represented by JQuranTree - are listed in the following tables:
| Character | Glyph | Description |
| Alif | 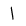 |
Arabic letter |
| Ba | 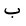 |
Arabic letter |
| Ta |  |
Arabic letter |
| Tha |  |
Arabic letter |
| Jeem | 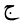 |
Arabic letter |
| HHa | 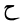 |
Arabic letter |
| Kha | 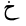 |
Arabic letter |
| Dal | 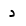 |
Arabic letter |
| Thal | 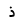 |
Arabic letter |
| Ra | 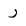 |
Arabic letter |
| Zain | 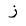 |
Arabic letter |
| Seen | 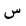 |
Arabic letter |
| Sheen | 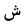 |
Arabic letter |
| Sad | 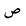 |
Arabic letter |
| DDad | 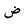 |
Arabic letter |
| TTa | 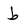 |
Arabic letter |
| DTha | 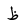 |
Arabic letter |
| Ain | 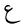 |
Arabic letter |
| Ghain | 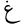 |
Arabic letter |
| Fa |  |
Arabic letter |
| Qaf | 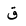 |
Arabic letter |
| Kaf | 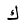 |
Arabic letter |
| Lam | 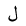 |
Arabic letter |
| Meem | 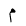 |
Arabic letter |
| Noon | 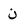 |
Arabic letter |
| Ha |  |
Arabic letter |
| Waw | 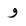 |
Arabic letter |
| Ya | 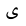 |
Arabic letter |
| Hamza | 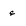 |
Arabic letter |
| AlifMaksura | |
Arabic letter |
| TaMarbuta | 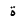 |
Arabic letter |
| Tatweel | 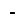 |
Orthographic
symbol used to lengthen the previous letter. In Tanzil XML, a diacritic hamza may sit on a tatwīl. |
| SmallHighSeen | 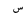 |
Quranic symbol |
| SmallHighRoundedZero | 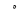 |
Quranic symbol |
| SmallHighUprightRectangularZero |  |
Quranic symbol |
| SmallHighMeemIsolatedForm | 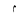 |
Quranic symbol |
| SmallLowSeen | 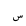 |
Quranic symbol |
| SmallWaw | 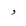 |
Quranic symbol |
| SmallYa | 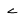 |
Quranic symbol |
| SmallHighNoon | 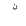 |
Quranic symbol |
| EmptyCentreLowStop |  |
Quranic symbol |
| EmptyCentreHighStop | 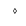 |
Quranic symbol |
| RoundedHighStopWithFilledCentre |  |
Quranic symbol |
| SmallLowMeem | 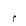 |
Quranic symbol |
Fig 3. Character types.
| Diacritic | Glyph | Description |
| Fatha | 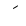 |
Above |
| Damma | 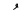 |
Above |
| Kasra |  |
Below |
| Fathatan | 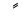 |
Double fatha |
| Dammatan | 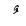 |
Double damma |
| Kasratan | 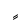 |
Double kasra |
| Shadda | 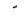 |
Above |
| Sukun | |
Above |
| Maddah | 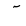 |
Above |
| HamzaAbove | 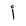 |
Above |
| HamzaBelow | 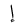 |
Below |
| HamzatWasl | 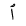 |
Above alif |
| AlifKhanjareeya | 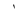 |
Superscript alif |
Fig 4. Diacritic types.
Locating Orthography Elements
Each element in the orthography model may be assigned a chapter number, verse number or token number. A 1-based numbering scheme is used, so that the first chapter, first verse or first token will have number 1 of the sequence. Sequence numbers may be used to access an element via the Document class:
// Get chapter 3. Chapter chapter = Document.getChapter(3); // Get verse (21:7). Verse verse = Document.getVerse(21, 7); // Get verse (2:14), token #2. Token token = Document.getToken(2, 14, 2);
Each element in the model has a getLocation() accessor which returns a Location object that specifies the current location. If a location is known, then static Document methods can be used to access an element by reference:
// Get verse (21:7) by location. Location location = new Location(21, 7); Verse verse = Document.getVerse(location);
Enumerating Orthography Elements
The orthography model can be considered as a flat list of verses and tokens, or can be navigated as a hierarchy of orthography elements. To treat the model as a flat list, use the following Document methods:
// Enumerate all chapters in the document.
for (Chapter chapter : Document.getChapters()) {
}
// Enumerate all verses in the document.
for (Verse verse : Document.getVerses()) {
}
// Enumerate all tokens in all verses.
for (Token token : Document.getTokens()) {
}
Alternatively, each element provides iterator methods which may be used to access those elements below. These methods include Chapter.iterator() and Verse.getTokens().
Working with Arabic Text
Instances of Arabic text are immutable since the orthography model can not be changed. Convenience methods are provided to create modified copies of the text. These include:
- removeDiacritics()
- Returns a copy of the text with diacritics removed.
- removeNonLetters()
- Returns a copy without Quranic symbols.
As with the rest of the orthography model, it is possible to enumerate over ArabicText. In this case, each individual character within the text may be accessed:
// Enumerate each character.
for (ArabicCharacter ch : text) {
}
The getType() method will return the type of each character, and accessors including isFatha() and isKasra() indicate which diacritics are attached to a letter. A character can also be accessed by its zero-based index, for example:
// Access the 3rd character. text.getCharacter(2);
This is analogous to the Java String.charAt()
method. In order to construct a new ArabicText
instance, the ArabicTextBuilder
class may be used.