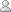

The syntax of traditional Arabic grammar is represented in the Quranic Arabic corpus using dependency graphs. Graphs are mathematical structures which consist of nodes and edges which link nodes together. In linguistic terms, a dependency graph is a way to visualize the structure of a sentence by showing how different words relate to each other using directed links called dependencies. In most variations of dependency grammar the nodes of a graph consist of words. That is, only links between words are allowed. However in traditional Arabic grammar the basic syntactic unit is not always a word. In most cases the syntactic unit is a morphological segment and the grammar explains how various segments are related across words. A syntactic unit may also be a complete word (with all its morphological segments) or a continuous sequence of words (such as a phrase or clause). This flexible approach to dependencies allows relations to be described between word segments, entire words or between phrases.
The diagram below is a simple dependency graph which describes the syntax of verse (112:2). The graph shows a dependency relation between the only two words in the verse, with the link pointing from the left dependent node to the right head node. In English a complete sentence requires a verb, but in Arabic the copula verb "be" is not required for present tense equational sentences, such as "God is the Eternal". In traditional Arabic grammar this is a subject-predicate relation mubtada wa-khabar (مبتدأ وخبر) with both nouns definite and in the nominative case marfūʿ (مرفوع):
| (112:2:2) l-ṣamadu the Eternal, the Absolute. | (112:2:1) al-lahu Allah, |
Fig 1. Dependency graph for verse (112:2).
Location References
Each morphological segment in the Quran is identified using a 4-part numbering scheme, as shown in gray above the English translation of each word. Also shown in the diagram is a phonetic transcription in blue directly above the Arabic words. The 4-part numbering scheme used is in the corpus is
(Chapter : Verse : Word : Segment)
A pair of numbers refer to a verse, three numbers refer to a word within a verse, and 4 numbers refer to a morphological segment within a word. For example:
- (112:2) – chapter 112, verse 2
- (112:2:1) – chapter 112, verse 2, word 1
- (112:2:2:2) – chapter 112, verse 2, word 2, segment 2
Heads and Dependents
In the Quranic Arabic corpus, each word is divided into morphological segments according to traditional Arabic grammar, and a part-of-speech tag in assigned to each segment. These segments form terminal nodes in a dependency graph. Non-terminal nodes are groups of words in sequence, such as phrases or clauses. Note that although the definite determiner (al-) is a morphological segment, it is not made into a node in the graph by convention since the determiner never forms part of a dependency relation in the grammar.
When there is a link between two words in a dependency graph, one is known as the head and the other is known as the dependent. In the Quranic Arabic corpus the convention used is that edges in a dependency graph point from the dependent node to the head node. The notation B → A means that B depends on A. A dependency graph with an edge B → A shows that the node B is at the end of an edge which points to A, and that B is the dependent node and A is the head node. As an example, because an adjective is dependent on the noun that it describes, any link between the two will always point from the adjective towards the noun. The adjective will be the dependent node and the noun will be the head node. Since Arabic is read from right to left, most links will point towards the right in the dependency graph of an Arabic sentence. This is because later words are most often dependent on words introduced earlier in the sentence. Each node in a graph may fill more than one syntactic function, as a node can be both a dependent node and a head node when considering different edges. More than one node can be dependent on the same head node. However
Each node in a syntactic dependency graph can point directly to at most one other node.
This means that a node cannot directly depend on two or more other nodes in the graph, and that each node has at most one unique head. A node without any head will be the root node of a subgraph.
Reference Nodes
A dependency graph will usually correspond to a single verse of the Holy Quran. Some of the larger verses may be split into several graphs, and two or more small verses may be joined into a single graph. However, there is no re-ordering of the original text in the corpus, nor are any words in the original text omitted. Often a word in one verse may have a relation to a word in another verse. For example, verse (1:3) of sūrat l-fātiḥah describes God as the "the most gracious, the most merciful", and these two adjectives refer to the proper noun introduced in the previous verse. Reference nodes are used to relate words from different dependency graphs. Referenced words are shown in gray since they are from another graph. The following dependency graph for verse (1:3) contains the word (1:2:2) as a reference:
| (1:3:2) l-raḥīmi the Most Merciful. | (1:3:1) al-raḥmāni The Most Gracious, | (1:2:2) lillahi (be) to Allah, |
Fig 2. A referenced word in the dependency graph for verse (1:3).
Elision (حذف) and Reconstruction (تقدير)
Hidden Nodes
There is no syntactic difference between normal nodes and reference nodes. It is possible to have relations between both types of node, as long as such links are permitted by traditional Arabic grammar, according to which word has been referenced. A hidden node is another type of node which is also shown in gray on the graph. The difference between hidden nodes and reference nodes, is that reference nodes are words from the Quran, while hidden nodes are extra words introduced by the grammar to make the syntactic analysis more explicit. Hidden words are most often pronouns and are already implied through inflection. The following dependency graph for verse (112:3) contains two hidden nodes:
| (112:3:4) yūlad He is begotten. | (112:3:3) walam and not | (112:3:2) yalid He begets | (112:3:1) lam Not |
Fig 3. Hidden pronouns in verse (112:3).
Classical Arabic is a pro-drop language. Certain verbs imply a pronoun subject through inflection and the pronoun can be dropped from the sentence. Traditional Arabic grammar restores these dropped words, and describes dropped pronouns as hidden damīr mustatir (ضمير مستتر). In the above graph there are two hidden pronouns which have been made explicit. Although both reference nodes and hidden nodes are shown in gray in the last two graphs above, only reference nodes will have a location number above them because they are actual words from the Quran.
Other parts-of-speech besides pronouns can function as hidden words, depending on the sentence being analyzed. In traditional Arabic grammar, hidden words omitted through elision are generally known as maḥ'dhūf (محذوف), and the process of reconstructing a sentence is known as taqdīr (تقدير). It is important to note that no new information or meaning is added through the syntactic reconstruction of a sentence. In some sense, reconstruction is a form of "syntactic normalization" which allows implicit syntactic roles to be made explicit, and allows grammatical constraints to be uniformly satisfied across all analyses.
Empty Nodes
Except for implied subject pronouns, hidden nodes do not usually have text associated with them. The actual hidden word itself is not usually important to the syntactic analysis, but the part-of-speech is. An empty node is a hidden node with only a part-of-speech tag, introduced to fill a syntactic function or semantic role. The dependency graph below for verse (1:1) includes an empty node:
| (1:1:4) l-raḥīmi the Most Merciful. | (1:1:3) l-raḥmāni the Most Gracious, | (1:1:2) l-lahi (of) Allah, | (1:1:1) bis'mi In (the) name |
Fig 4. An empty verb node in verse (1:1).
In the above syntactic analysis, an empty node has been introduced. Empty nodes are by convention shown using the asterisk star symbol (*). The empty node used above is an implied verb to which the following preposition phrase (PP) is attached. According to traditional Arabic grammar, the verb is hidden maḥ'dhūf (محذوف). Except for implied subject pronouns, usually only the part-of-speech of a hidden word is important. Postulating the actual text of a hidden word could suggest a different meaning for a verse, and is for the most part avoided by linguists performing traditional Arabic grammar analysis.
Phrases and Clauses
Phrase Nodes
Most relations in a dependency graph will be between terminal nodes. These are nodes which correspond to morphological word segments and will have part-of-speech tags. Since traditional Arabic grammar often describes relations between phrases, a dependency graph may also include non-terminal phrase nodes. Phrase nodes are shown under horizontal blue bars as can be see in figures 3 and 4 above. The extent of the bar shows which words or word segments form the phrase. Using phrases is a natural way to relate two groups of words, for example when one clause is connected to another through conjunction. Another good use of phrases is to describe preposition phrase attachment, where the preposition and its genitive noun form a preposition phrase (PP).
Phrasal nodes are non-terminal nodes, and group together a continuous sequence of terminal nodes. That is, a phrase is always made up of several words together in sequence. Hierarchies of phrases are not permitted, so that a phrasal node is always made up of terminal word nodes. Each phrase node is annotated using a corresponding phrase tag.
Summary
The following definitions explain the different types of node used in dependency graphs:
- terminal nodes correspond to word segments and will always have a part-of-speech tag.
- phrase nodes are non-terminal nodes formed by grouping together a sequence of consecutive terminal nodes, and will always have a phrase tag.
- reference nodes are nodes from another dependency graph, used to show relations between words across verses.
- hidden nodes are implicit words with a part-of-speech tag and Arabic text, used to fill a syntactic function or semantic role.
- empty nodes are hidden nodes without any associated text and only a part-of-speech tag, by convention labelled as (*).